AI Overview
This article explains how to plan and implement disaster recovery (DR) strategies on Google Cloud. It covers different DR patterns and when to use each based on business needs. It also highlights key considerations for recovery time, data protection, and cost efficiency. Readers will learn how to build resilient cloud systems that can withstand failures and minimize downtime.
Cloud computing is built around resilience and avoiding complete failures. Unfortunately, despite best efforts, critical failures are always a possibility, due to anything from a national power outage to a natural disaster. Regardless of the cause, when things begin shutting down, businesses need to have the peace of mind that their data and infrastructure would recover safely and without hurdles.
That said, every business is different and so disaster recovery plans have to be as well. In addition to a lot of customizability, Google Cloud offers three fundamentally different types of DR patterns that businesses can use as the foundation for their long-term DR plans. For implementing the right strategy, many organizations rely on strategical advice from our experts through Google Cloud Assessment Services to ensure effective planning and resilience.
In addition to the extensive range of options, Google Cloud also offers tools for testing and deployment that help businesses effectively design a comprehensive and well-tested disaster recovery plan for on-premise applications and mitigate any potential losses.
In this article, we’ll take a brief look at what Disaster Recovery is and a closer look at the different types of DR patterns available.
Disaster Recovery Overview
Disasters like power outages , Floods , Earthquakes can have a huge impact on your business, especially when you have a strong online presence. Naturally then, steps need to be taken to make sure the impact on the business. This is what the Disaster Recovery plan is responsible for.
Disaster Recovery is defined as the amount of impact a business can take during a disaster. There are two key metrics that define this impact: RTO and RPO.
Recovery Time Objective (RTO):- RTO is defined as the maximum amount of time the application can be offline as defined by the SLAs that you, as a service provider, have offered to your customers.
Recovery Point Objective (RPO): – RPO is defined as the maximum amount of time during which the service might be lost during an interruption.
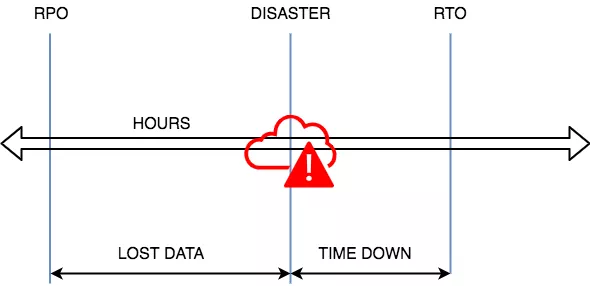
As suggested in these two figures, a lower RTO would mean less time allowed for the system to recover. Similarly, with a lower RPO, less data would be lost from the service disruption.
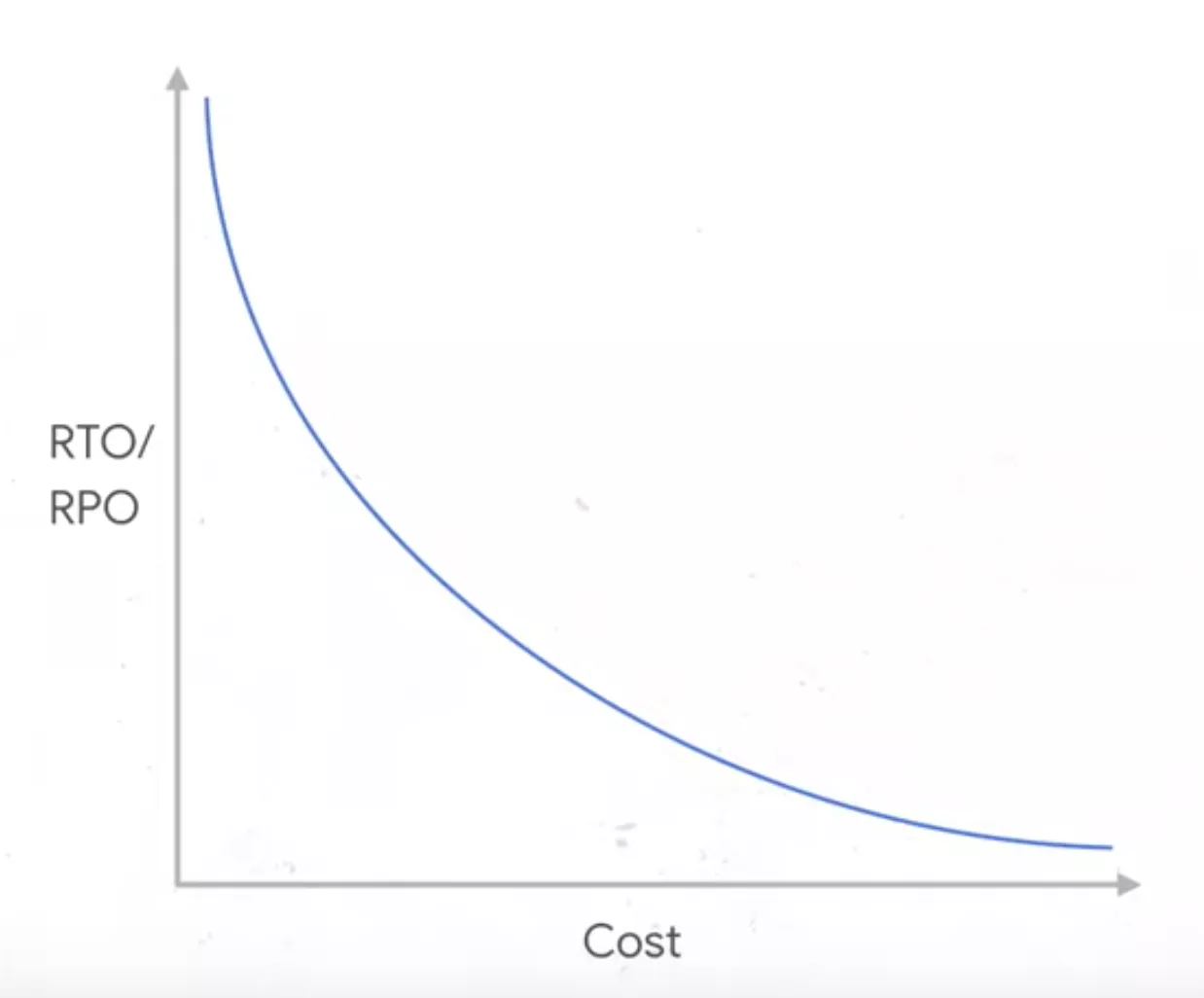
The lower RPO/RTO values thus means that a company would incur higher costs in maintaining the Infrastructure setup/configuration required to meet the strict SLAs.
On the other end, higher RPO/RTO values would indicate lax SLAs and thus more time for the disaster recovery plan to kick into action. But this also means that your service stays offline for longer and customers won’t be able to access their data. Stricter SLAs are also an important selling point in today’s competitive landscape.
Using Google Cloud for Disaster Recovery
Google Cloud as a Disaster Recovery (DR) solution is a great idea for almost every company as it ensures far lower RTO and RPO values compared to traditional on-premises DR solutions without astronomical prices.
Following is a brief description of some of GCP’s distinguishing DR features:
Global Network
Google’s Virtual Private Network is global in nature eliminating the need to set up complex connectivity between GCE VMs residing in two between regions for example. They can directly talk to each other via private RFC addresses.
Redundancy
Redundancy is offered as a built-in optional feature for some of the GCP services while for others like compute resources can be provisioned in multiple zones ( to be resilient to the zonal outage).
Scalability
Scale with Google’s global load balancer (GCLB) and autoscaling, available with Managed Instance Groups or other options
Security and Compliance
Security is offered at every layer within GCP. Physical security at disks level, security for APIs in the form of SSL, service to service communications with service accounts, data Encryption offered by default, and several compliance standards like HIPAA, SOC-1, FedRamp, ISO/IEC 27001
Types of DR Patterns
Design patterns are standard methods of solving common problems. For disaster recovery, there are three main patterns: cold, warm, and hot. Moving from cold to hot, patterns become increasingly comprehensive and cover a wider range of scenarios with the focus of achieving near zero RTO and RPO values.
Hot Disaster Recovery
Best solution achieved by running a High Availability (HA) environment concurrently across GCP and on premises.
Very small to near zero RTO and RPO values
Warm Disaster Recovery
Standby option with minimum RPO and RTO without the expense of a fully HA configuration.
Medium RTO and RPO value
Cold Disaster Recovery
Minimal resources on Google Cloud just enough to enable the recovery scenario
Low cost with high RTO and RPO values
Before we take a closer look at these patterns, it’s a good idea to understand the best practices that apply to every DR strategy:
Best Practices for DR Strategy
The following is a list of best practices that we at D3V apply when planning out disaster recovery strategies for our partners and should be very helpful for businesses looking to develop their own strategies:
Define your own RTO & RPO values
RTO and RPO aren’t simple metrics that can be calculated through a universal method. SLAs can vary a lot from industry to industry and thus it’s important that you define your own RTO and RPO values as per your business requirements and what they’ll mean.
Create a full end-to-end recovery plan
DR plans can vary in depth or complexity (as we’ll when we discuss cold, warm, and hot patterns) but they should all be complete, end-to-end recovery plans and cover the entire process of getting your systems to a pre-disaster state.
Make the recovery tasks precise and concrete
The recovery plan is meant to be a strategy, not a policy. This means that it should contain clear and precise steps that the IT staff needs to take in case of a disaster instead of containing general, broad guidelines. For example, the path for the recovery scripts and commands that need to be executed should be clearly laid out.
That said, many companies will supplement this information with qualitative policy that will help staff find solutions to problems that may be outside the DR plan (although the plan should be comprehensive enough that this does not happen).
Implement control measures
Companies should also implement measures such as monitoring health and sending alerts when a critical event takes place, such as spikes in traffic or deletion of user data.
Execute a dry run
It’s always recommended that companies plan and execute a dry run before fully relying on the DR plan. Start by preparing the software and making sure to install from the source or use a pre-configured image. You also want to make sure to have multiple paths for data recovery.
Additionally, ensure you have the appropriate licenses for that deployment before evaluating the continuous deployment toolset available within GCP.
Cold Disaster Recovery
Simply put, cold disaster recovery means that you are not fully prepared to handle a complete system failure on your own. It’s the bare minimum that every company must do in order to ensure their on-premise applications can be recovered after a failure by a third-party.
Prerequisites
Hybrid connectivity using one of the options Cloud VPN , Dedicated Interconnect or others as per your business needs. This is needed to setup replication of on premise database server.
GCS bucket to store database backups and snapshots
How to Prepare for a Cold Disaster Recovery?
Create a VPC network. Configure hybrid connectivity between the on premise setup and GCP using any of the hybrid connectivity options ( Dedicated interconnect, Cloud VPN etc).
Create a GCS bucket as a target for the backup data( DB backups).
Setup an IAM service account key to be used by automation script on premise to be able to upload database backups to GCS . Use IAM policies to restrict access to the right user as well as ensure service accounts have minimal permissions required. Make sure uploads and downloads to and from the GCS bucket are working.
Finally script to do data transfer of database backups to GCS bucket.
Create a scheduled task to run that script.
Created custom images that are configured for each type of server in the production environment on premise.
Configure DNS to point to internet facing web servers on premise
Create a deployment manager template that will create servers in Google cloud network using the previously configured custom images.
When a disaster strikes, execute the deployment manager template which will create a google cloud deployment automatically.
Apply most recent database backups and transaction logs from the GCS bucket.
Test the application works as expected by simulating a user in the recovered environment.
Finally point the Cloud DNS to the web server on Google Cloud.
When the production environment is back up, reverse the steps:
Take a backup and transaction logs of the database running on Google Cloud
Copy and apply the backup to DB in prod environment
At this stage prevent connections to applications on Google Cloud
Warm Disaster Recovery
A warm disaster recovery is where we begin to see improvements in RTO and RPO values, dropping them significantly. A warm disaster recovery involves establishing the tools and services required to conduct a full recovery. The main downside being that your service stays offline during the entire recovery process.
Prerequisites
Cloud DNS GCP service
Hybrid connectivity using one of the options Cloud VPN , Dedicated Interconnect or others as per your business needs. This is needed to setup replication of on premise database servers.
How to Prepare for a Warm Disaster Recovery?
Create a VPC network. Configure hybrid connectivity between the on premise setup and GCP using any of the hybrid connectivity options ( Dedicated interconnect, Cloud VPN etc)
Replicate the on premise servers to the compute engine instances on GCP
Create snapshots of the web and application server instance on GCP
Create a custom image of the database server on GCP with the same configuration as on premise.
Start a GCE VM using the above custom database image. Attach a persistent disk to the database instance for database and transaction logs.
Configure the replication of the database server. Configure autoDelete flag on the persistent disk to No-AutoDelete to prevent deletion of the persistent disk
Configure a scheduled task to create regular snapshots of the persistent disk of the database instance on GCP.
Test the process of creation of the GCE VM instances for web and application servers from the VM snapshots created in step 3 above.
Create a script that copies updates to the application and web server whenever the corresponding on premise servers are updated.
Write a script to create snapshots of the updated servers.
Configure Cloud DNS to point to the Internet facing web service on premise
Once a disaster strikes follow the below steps
Resize DB instance size to handle production load
Use the web and app server snapshots to create new web and application server instances.
Test that the instances work
Point the Cloud DNS to web service on Google Cloud. Failover to GCP is now complete.
Once on premise site can support running production workloads again follow the below steps to redirect
Take a backup of the database running on GCP. Copy and apply the backup file to the on premises database instance.
Prevent connections to applications running on Google Cloud for example by modifying firewall rules to prevent access to web servers. From this point the application is now unavailable until we finish restoring the on premise environment.
Don’t forget to copy any transaction logs from GCP to on premise and apply to database instance on premise
Test application works as expected by simulating user scenarios
Configure Cloud DNS to point to on premise web service. Failover to on premise is now complete.
Delete the web server and application server instances that are running in Google Cloud
Resize the database instance back to the minimum instance size that can accept replication traffic from the on premise production database
Hot Disaster Recovery
A hot disaster recovery aims to achieve the lowest or near zero RTO or RPO values which means that the recovery begins as soon as the failure happens and brings the system/service back online almost instantaneously albeit not to its full capacity or performance (depending on your configuration).
A hot disaster recovery plan is thus essential for businesses that guarantee high availability of 99% and above.
Prerequisites
Need to use a DNS service that supports weighted routing ( to route between on premise and GCP)
Hybrid connectivity using one of the options Cloud VPN , Dedicated Interconnect or others as per your business needs to setup replication of on premise database server.
How to Prepare for a Hot Disaster Recovery?
Create a VPC network. Configure hybrid connectivity between the on premise setup and GCP using any of the hybrid connectivity options ( Dedicated interconnect, Cloud VPN etc)
Create custom images of the web server and application server with exact same configuration as their peers residing on premise
Setup replication of the database server between on premise and GCP . If your database servers permit only a single writable database when you configure replication then you might need to configure one of the database servers as a read only replica
Create individual instance templates that use the images for the application server and the web server
Configure Regional Managed Instance Groups ( MIG) for the application server and the web server. Also setup health check with Stackdriver Monitoring.
Setup a Regional load balancer for the Managed Instance Group
Setup a scheduled task to create regular snapshots of the persistent disk ( for the database)
Lastly setup a DNS service with weighted routing between the production applications deployed on premise and the GCP environment
In case of a failure on premise ( DR scenario) disable the DNS service for on premise and entire traffic will failover to GCP.
In the event of the on premise application coming back up all you need is to change the DNS weightage to route both to on premise and GCP (HA setup).
Wrapping up…
Every company should have a Disaster Recovery plan. Hopefully, this article gave you the necessary understanding to build your own. Though if you are still a bit hesitant to tackle it yourself, we recommend exploring our Google Disaster Recovery Services or then contact us for free consultation.
