AI Overview
This article explains trunk based development and its role in progressive delivery. It covers faster integration, fewer conflicts, and continuous deployment. It shows how teams can release features more safely. It helps improve development speed and quality.
During the early days of using software development in organizations, programmers kept track of all the changes made in their software by developing new versions. However, this process proved to be an inefficient use of time and money which made development costly to the organizations.
Over the years, several development styles have emerged that enabled developers to find bugs and errors in an efficient way and to code and make changes in parallel with their fellow developers, significantly speeding up releases.
Today, however, most developers leverage one of two development models – Gitflow and trunk-based development. In this technical guide, we’ll take a closer look at the progressive delivery method of trunk-based development, its benefits, and how it stacks up against Gitflow.
What is Trunk-based Development?
Trunk-based development is a version control management practice where developers merge small, frequent updates to a core “trunk” or main branch. Since it streamlines merging and integration phases, it helps achieve CI/CD and increases software delivery and organizational performance.
In many ways, it is a way of extreme source control technique in which all the developers of an organization collaborate to grow and maintain the main branch of the software directly in their source control (git) or also known as “the trunk”, making creating and merging additional branches unnecessary.
Trunk-based development is not a new branching model in software development. The word ‘trunk’ is referred to the concept of a growing tree, where the fattest and longest span is the trunk, not the branches that radiate from it and are of more limited length.
Shared branches off mainline/master/trunk are bad at any release cadence:
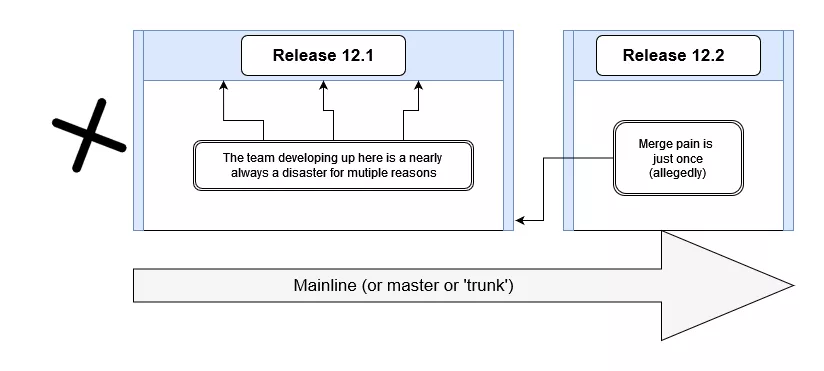
In the above diagram, there are multiple branches to commit the changes and these changes are done by multiple developers and all these commits become a mess while merging to the main branch.
Trunk-based Development For Smaller Teams
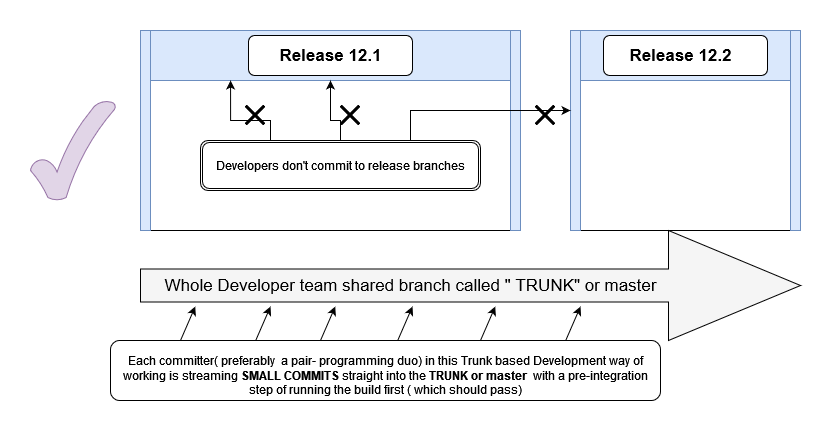
Trunk-based development is a key enabler of Continuous Integration and by extension Continuous Delivery.
When individuals on a team are committing their changes to the trunk multiple times a day it becomes easy to satisfy the core requirement of Continuous Integration that all team members commit to trunk at least once every 24 hours.
This ensures the codebase is always releasable on demand and helps to make Continuous Delivery a reality. In the above below, we can see how trunk-based development works for Continuous Integration pipelines.
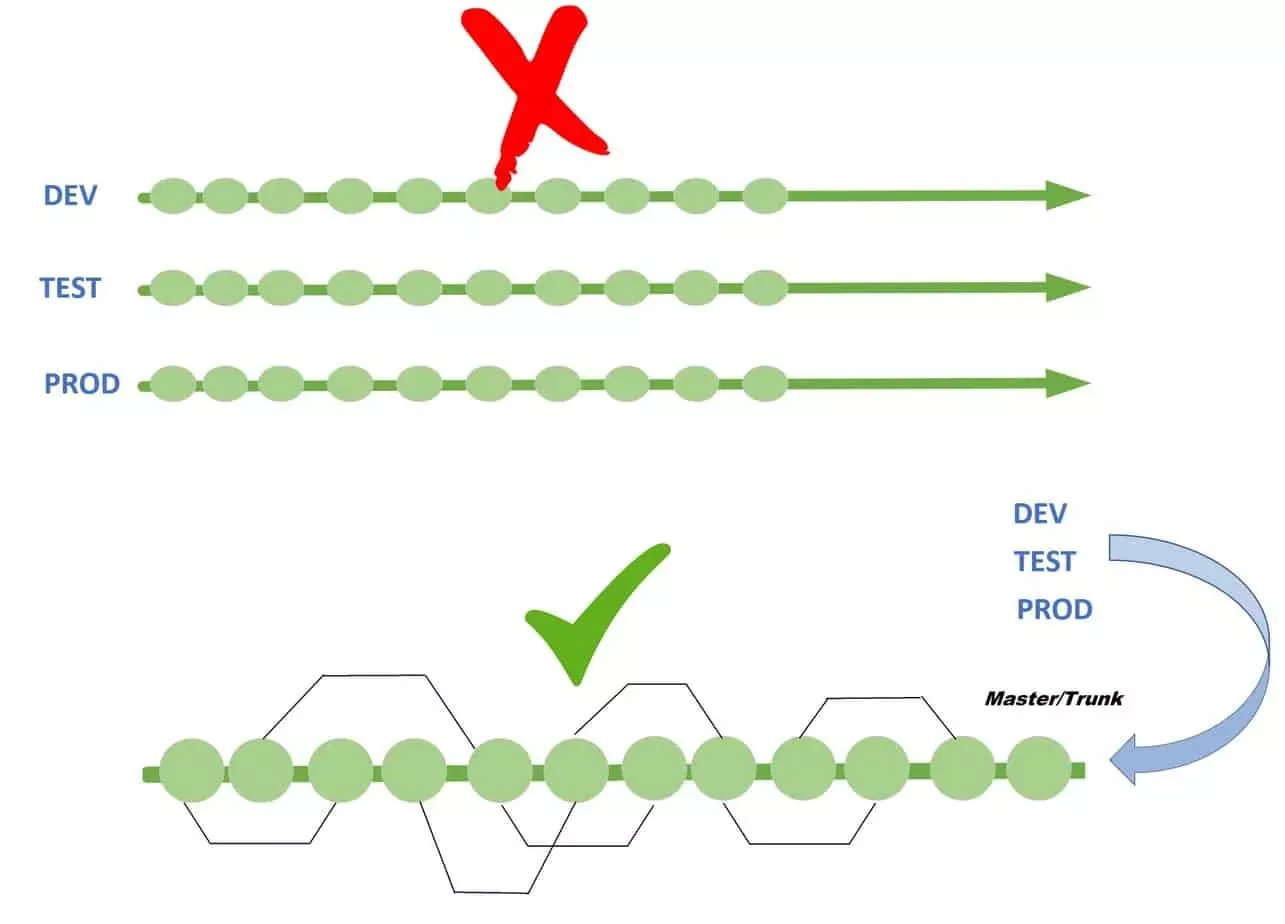
Differences on Gitflow and trunk-based development
Gitflow is a git branching model that uses feature branching i.e., long-lived branches and multiple branches. It has separate primary branch lines for development, features, releases, etc. There are different strategies for merging commits between the branches. Since there are more branches to juggle and manage, there will be more complexity that requires additional planning from the developers and programmers team.
Trunk-based development is far more simplified as it focuses on the main branch as the source of fixes and releases. In trunk-based development, the main branch is assumed to always be stable, without issues, and ready to deploy.
Prerequisites for Trunk-based Development
There’s more to adopting trunk-based development than deciding to do away with branching and commit to the trunk. You need to have the right prerequisites in place to make it work. These prerequisites include:
- A team of experienced and confident developers who trust each other’s work
- A loosely-coupled code base that can support feature abstractions
- A robust solution for feature flags (e.g. Launch Darkly or Flagr)
- Process surrounding Feature Flagging
- A continuous build and test infrastructure that can keep up with a high rate of commits.
- Streamlined processes around review and release that don’t hold up the rate at which commits can be ingested.
- Cultural change, Comprehensive automatic unit, and Integration testing
- A fail-safe mechanism for Blue-Green Deployment.
Benefits Of Trunk-based Development
The following is a list of best practices that we at D3V apply when planning out disaster recovery strategies for our partners and should be very helpful for businesses looking to develop their own strategies:
Simplicity
Trunk-based development is a very simple technique. Without branches, all that developers have to do from the technical point of view is commit and push their code, always to the same branch.
Merging issues become less likely
When working branches, we need to synchronize our branches in case something has changed. In trunk-based development since there are fewer layers in the source control tool, the likelihood of working in code that is out of sync is significantly less. This means fewer merging issues.
Faster integration
In trunk-based development, we don’t need to do pull requests, the integration tends to be quicker. It is first come first served. Before we push to the main/trunk we don’t have intermediate branches adding complexity to the process and also slowing down the delivery.
Testers feel it efficient
Many testers find it quite confusing when working with branches. They want to test something but they are unsure from which branch they should pull the code and also from which branch they should pull the dependencies. In trunk-based development the trunk is always green, the testers can safely always be confident that they are testing the latest.
Higher code quality
If something breaks, we need to fix it straight away because the build will go red. and the pipeline will stop. The testers will not be able to test and the DevOps team won’t be able to deploy. Trunk-based development provides the highest quality code because we have to run the tests locally first and make sure that all is in order before we can push the code.
Shared ownership for developers
Once the team is happy with the current state of the trunk, it can choose to create a tag. The important thing is that trunk-based forces the whole team to have a better awareness of what is going on.
Better automated tests
In order to do trunk-based development successfully, we will need really good automated tests, especially acceptance tests. This technique forces us to be very ready about our requirements with the Business Analysts and have them continuously involved in the process of discovering, crafting and updating requirements. This high degree of interdisciplinary collaboration that trunk-based development requires is great for sharing knowledge and tackling issues if any.
Allows continuous code integration
In the trunk-based development model, there is a repository with a steady stream of commits flowing into the main branch. Adding an automated test suite and code coverage monitoring for this stream of commits enables continuous integration. When new code is merged into the trunk, automated integration and code coverage tests are run to validate the code quality.
Pairing
Many teams that practice trunk-based development also do pair programming as a rule of thumb. The reason for this is because with pair programming we have a more immediate continuous code review always ongoing which is essential for trunk-based development.
So as you see trunk-based development is simple but yet very powerful. But not every company and team is in the position of doing it because of multiple reasons.
Wrapping up…
Trunk-based development is presently the standard for high-performing teams since it sets and maintains a software release cadence by using a simplified Git branching strategy. Moreover, trunk-based development gives teams more flexibility and control over how they deliver software to the end-user.
If you’d like to learn more about faster software delivery and how your business can significantly improve its time-to-market, quality of updates, and overall software development efficiency, reach out to D3V’s cloud-certified engineers today for a free consultation.