AI Overview
This article provides a technical guide to setting up NATS Streaming Server on GKE. It covers deployment architecture and configuration steps. It explains how NATS enables reliable messaging in distributed systems. It helps teams build scalable event driven applications.
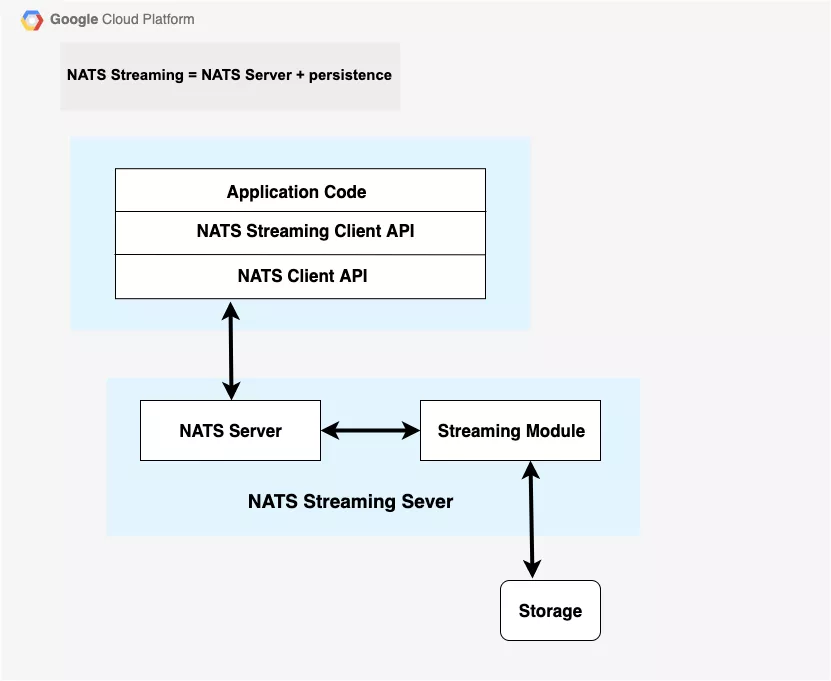
NATS Streaming is a data streaming framework powered by NATS. It is an open-source messaging system written in Go programming language. The feasible name for NATS is “nats-streaming-server”. NATS Streaming inserts, expands, and interoperates flawlessly with the core NATS platform. NATS is an open-source software provided under the Apache-2.0 license. NATS stands for Neural Autonomic Transport System.
Why Do Businesses Deploy NATS?
NATS Streaming is a versatile system with numerous benefits including granting businesses abilities such as:
Magnify message protocol
It implements its own way to magnify Google Protocol buffers message format (Protocol buffers are a language-neutral, platform-neutral extensible mechanism for serializing structured data). These messages pass on as binary message payload through the core of NATS platform, and this is why there are no changes required for the basic NATS protocol.
Message/event persistence
NATS offers customization for the messages with several options for persistence like database, in-memory or flat files. The storage subsystems use public links or interfaces that allow developers to develop their own ideas and make custom implementations.
At-least-once-delivery
NATS Streaming server delivers message acknowledgements between publisher and server (for publish operations) and between subscriber and server (to confirm message delivery). Messages are persisted by the server in primary storage or secondary storage (means any other external storage) and will be delivered again to eligible subscribing clients when needed.
Publisher rate limiting
NATS also provides a connection option known as MaxPubAcksInFlight that successfully limits the number of unacknowledged messages a publisher may have in-flight at any given period of time. When it reaches its maximum, further async publish calls will stop until the number of unacknowledged messages falls below the some specified limit.
Rate matching/limiting per subscriber
With this feature, Subscriptions may describe a MaxInFlight option that selects the maximum number of outstanding acknowledgements (messages that have been delivered but it is in unacknowledged state) that NATS Streaming server will allow for a given subscription. When this limit is reached, NATS Streaming will stop delivering the messages to this subscription until the number of unacknowledged messages falls below the specified limit.
Historical message replay by subject
When a new subscription comes in, NATS allocates a beginning spot in the stream of messages stored for the subscribed subject’s channel. By using this choice, message delivery may begin at:
- The earliest message stored for this subject
- The most recent stored message for this subject, prior to the beginning of the current subscription. This is commonly thought of as “last value” or “initial value” caching.
- A specific date/time in nanoseconds
- An historical offset from the current server date/time, example the last 45 seconds.
- A specific message series number
Durable subscriptions
Subscriptions can also specify a “durable name” which will get through client restarts. Durable subscriptions enable the server to follow the trail when the last acknowledged message series number for a client and durable name. When the client reopens or resubscribes, and uses the same client ID and durable name, the server will start the delivery with the earliest unacknowledged message which is in sequence for this durable subscription.
When to Use NATS Streaming Server?
Some of the most popular business use cases for a NATS streaming server include:
- When a consumer replays their replay of data and we need to stream historical data
- When a producer is sometimes offline, then an initialization is required when the last message is produced on a stream
- When the data producers and consumers are online at different times and consumers must receive messages.
- Applications need to use up data at their own speed
Common Problems Faced During NATS Server Set-Up (and their Solutions)
Cloud engineers and developers can face a number of problems when setting up their NATS streaming server. Following are the most common issues along with how to solve them:
Connection Errors
When the NATS setup is using the Linux version of the docker image, engineers may face frequent connection errors.
Solution: To overcome this problem, shift to the nats-streaming:0.21.2-alpine docker image
Connection Failure Due to Separate Storage
Configurations that use Fault Tolerance mode in NATS streaming needs shared disks among all the NATS streaming servers. However, if the deployment has separate storage per instance of the server, some connections may fail to connect.
Solution: Migrating from GCE Persistent disks to the Cloud FileStore managed service on Google Cloud should solve this problem. Cloud FileStore is a NFS based NAS storage implementation and works well with GKE.
Using GCE Persistent Disk
If you are using GCE persistent disks which only support ReadOnlyMany and not ReadWriteMany, then using the ReadOnlyMany option can cause the NATS server deployment to fail.
Solution: Switch to Cloud Filestore managed service in GCP Instance that supports “ReadWriteMany” access Mode.
Two Ways of Setting Up NATS Streaming Server in GKE
There are two ways to set up a NATS streaming server in Google Kubernetes Engine:
Clustering Mode
In clustering mode, the data is distributed and replicated across servers using Raft consensus algorithm. In case one server fails, other servers can handle the client request/connections.
Fault Tolerance Mode
NATS Streaming server can also be run in Fault Tolerance (FT) mode by forming a group of servers with one being the active server, and all others acting as standby servers. This helps us overcome the single point of failure.
The active server in the Fault Tolerance group (FT group) accesses the persistent store and handles all communication with clients while all standby servers detect an active server failure in the background.
We can have multiple standby servers in the same Fault Tolerance group. When the active server in the FT group fails, all standby servers will try to become active, then one server will become an active server and recover the persistent storage and service all clients. In order to use a shared state of persistent storage for an FT group, the data store needs to be mounted by all servers in the FT group.
To help you choose the right installation mode, here is a quick comparison between the Clustering and Fault Tolerance modes:
| Feature | Clustering Model | Fault Tolerance (FT) Model |
|---|---|---|
| Data Distribution | Data is replicated across servers using RAFT Algorithm | |
| Underlying Storage | FileStore Mode Can be NFS or filesystem basedSqlStore Mode Can be MySql or Postgres. Needs a separate DB instance per server |
FileStore Mode Need to use NFS based storage only like Cloud FileStore in GCPSqlStore Mode Can be MySql or Postgres. The same DB is shared across all instances. |
| HA (High Availability) | Used to provide HA | Provides HA with Active and standby servers |
| Performance and failover | Lower performance compared to FT model | For NATS Streaming this is the recommended setup by docs to achieve better performance and failover |
Steps to Setup NATS in Google Kubernetes Engine Cluster
We need to create Filestore Instance
Firestone is a fully managed, NoOps network-attached storage (NAS) for Compute Engine and Kubernetes Engine instances. Firestone enables developers to easily mount file shares on Compute Engine VMs. Filestore is also tightly integrated with Google Kubernetes Engine so containers can reference the same shared data.
To create a Firestone instance, follow these steps:
Set Instance ID to nats-storage
Set Instance type to Basic
Set Storage type to HDD
Set Allocate capacity to 1TB (It is a minimum size for HDD)
Set Region to us-central1
Set VPC network to default
Set File share name to nats_filestore
Set Allocated IP range to Use an automatically allocated IP range
Final step is to click on Create and that’s it – your Firestone instance is created.
Create a Persistent Volume YAML file
apiVersion: v1
kind: PersistentVolume
metadata:
name: fileserver
spec:
capacity:
storage: 1T
accessModes:
- ReadWriteMany
storageClassName: standard
nfs:
path: /nats_filestore
server: # IP address Filestore instance
Now create YAML file to claim the above persistent volume
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: fileserver-claim
spec:
accessModes:
- ReadWriteMany
storageClassName: standard
volumeName: fileserver
resources:
requests:
storage: 500Gi
Create the deployments file for NATS using the above claim volume as a storage
apiVersion: apps/v1
kind: StatefulSet
metadata:
generation: 9
labels:
app: nats-streaming-ft
name: nats-streaming-ft
namespace: default
spec:
podManagementPolicy: OrderedReady
replicas: 3
revisionHistoryLimit: 10
selector:
matchLabels:
app: nats-streaming-ft
serviceName: nats-streaming-ft
template:
metadata:
creationTimestamp: null
labels:
app: nats-streaming-ft
spec:
containers:
- args:
- -cid=test-cluster
- -m=8222
- -mc=10000
- -msu=0
- -mi=24h
- -max_age=24h
- -store=FILE
- --dir=/nats-filestore
- --file_fds_limit=0
- -ft_group=ft-test
# - --cluster_raft_logging=true
- --cluster=nats://0.0.0.0:6222
- --routes=nats://nats-streaming-ft:6222
image: docker.io/nats-streaming:alpine
imagePullPolicy: IfNotPresent
name: nats-streaming
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /mnt/fileserver
name: nats-filestore
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
volumes:
- name: nats-filestore
persistentVolumeClaim:
claimName: fileserver-claim
readOnly: false
updateStrategy:
rollingUpdate:
partition: 0
type: RollingUpdate
Create a service file for NATS
apiVersion: v1
kind: Service
metadata:
labels:
app: nats-streaming-ft
name: nats-streaming-ft
namespace: default
spec:
ports:
- name: tcp-nats
port: 4222
protocol: TCP
targetPort: 4222
- name: tcp-nats-cluster
port: 6222
protocol: TCP
targetPort: 6222
- name: tcp-monitoring
port: 8222
protocol: TCP
targetPort: 8222
selector:
app: nats-streaming-ft
sessionAffinity: None
type: ClusterIP
status:
loadBalancer: {}
Deploy the above files using kubectl commands
# kubectl apply -f persistent-vol.yaml
# kubectl apply -f persistent-vol-claim.yaml
# kubectl apply -f nats-deployment.yaml
# kubectl apply -f service.yaml
And with this, your NATS deployment is set up correctly.
How to Monitor a NATS Server After Initial Setup
To monitor your NATS server after your initial set up is complete, follow these steps:
Check the logs of nats-streaming-ft microservice, if you do not find anything move to Step 2
Go to the nats-streaming service column and then the Ports section. There should be a monitoring port that opens in web preview
Assuming a 3 node NATS cluster we can connect to each of them by running the following commands
Deploy the above files using kubectl commands
For Node 1:
# gcloud container clusters get-credentials --zone us-central1-a --project \
&& kubectl port-forward $(kubectl get pod --selector="app=nats-streaming-ft" \
--output jsonpath='{.items[0].metadata.name}') 8080:8222
For Node 2:
# gcloud container clusters get-credentials --zone us-central1-a --project \
&& kubectl port-forward $(kubectl get pod --selector="app=nats-streaming-ft" \
--output jsonpath='{.items[1].metadata.name}') 8081:8222
For Node 3:
# gcloud container clusters get-credentials --zone us-central1-a --project \
&& kubectl port-forward $(kubectl get pod --selector="app=nats-streaming-ft" \
--output jsonpath='{.items[2].metadata.name}') 8082:8222
NATS monitoring will be accessed with the following links
- Node 1: localhost:8080
- Node 2: localhost:8081
- Node 3: localhost:8082
The /route endpoint should have 2 routes for each node.

Wrapping up…
Without proper knowledge of Google Kubernetes Engine and NATS steaming server, it can be difficult to deploy NATS. The set up has various problems, solutions of which are sometimes not obvious. Additionally, without the right background and knowledge of Cloud Operations (GCP service), tracing failures and errors back to the microservices can be even more difficult.
With this guide, we hope to help companies deploy a NATS streaming server in their cloud infrastructure. However, if you do not have an existing team of cloud engineers, it may be worthwhile to consult with one to avoid the future cost of failed deployments and communications errors.
If you’d like to learn more about how you can fully utilize a NATS streaming server in your business, reach out for a free consultation with our certified cloud engineers today.
Real outcomes with GKE: A customer snapshot : see how D3V helped deliver measurable results with a custom GKE backend solution.
