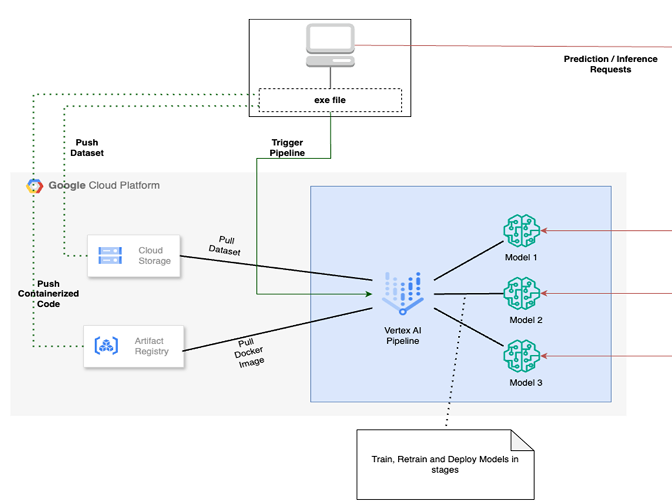
This document outlines a comprehensive roadmap for establishing a robust MLOps practice. The focus is on leveraging Google Cloud Platform’s (GCP) Vertex AI suite to build scalable, maintainable ML pipelines for custom models. This approach transitions development from manual, notebook-based experimentation to a structured, automated, and enterprise-ready workflow.
MLOps Roadmap Overview
The proposed MLOps process follows a standard lifecycle, specifically adapted for handling data and specialized classification or segmentation models:
- Data Foundation & Preparation: Secure ingestion, storage, and versioning of data.
- Model Development & Training: Creating custom models using managed GCP infrastructure.
- Evaluation & Testing: Rigorous performance assessment against clinical benchmarks.
- Deployment & Serving: Transitioning models to scalable, secure endpoints.
- Monitoring & Iteration: Continuous tracking of drift and automated retraining.
Step-by-Step Implementation on GCP
Step 1: Data Foundation & Preparation
GCP Services:
- Cloud Storage (GCS): Acts as the primary repository for raw and processed data. It stores versioned datasets and training splits. Security is managed via strict IAM controls and Customer-Managed Encryption Keys (CMEK).
- BigQuery: Stores structured metadata (demographics, acquisition parameters, ground truth labels). It is ideal for combining imaging features with tabular data for large-scale analytics.
- Cloud Functions / Cloud Run: These services automate ingestion and pre-processing tasks, such as resizing, normalization, and data augmentation (flips, rotations, contrast adjustments).
Step 2: Model Development & Training
Goal: Train custom models for specialized tasks such as image classification, object detection, or segmentation
GCP Services:
- Vertex AI Notebooks: A managed JupyterLab environment pre-installed with TensorFlow, PyTorch, and scikit-learn for interactive prototyping.
- Vertex AI Training: Handles scaling of training jobs using custom containers. It provides access to high-performance GPUs (NVIDIA L4, T4, A100) and supports distributed training for complex deep learning architectures.
Step 3: Evaluation & Testing
Goal: Ensure reliability and relevance before deployment.
- Metrics: Focus on Precision, Recall, F1-Score, and ROC AUC for classification. For segmentation, metrics include the Dice Coefficient and Intersection over Union (IoU).
- Data Integrity: Strict patient-level splits are implemented to prevent data leakage.
- Qualitative Review: Domain experts review segmentation masks and classification heatmaps to ensure the model aligns with clinical reality.
- Fairness Audits: Analysis of performance across demographic subgroups to ensure equity in outcomes.
Step 4: Deployment & Serving
Goal: Provide secure, scalable access to models for research integration.
GCP Services:
- Vertex AI Model Registry: A central repository to version models and store associated metadata (training data, metrics, code).
- Vertex AI Endpoints: Provides managed HTTP/S endpoints for predictions. It supports traffic splitting for safe rollouts and autoscaling to handle varying request volumes.
Step 5: MLOps, Monitoring & Iteration
Goal: Automate the lifecycle and detect performance degradation.
GCP Services:
- Vertex AI Pipelines: Orchestrates the workflow using Kubeflow Pipelines (KFP) or TFX. Pipelines are triggered by new data arrival or performance drops.
- Vertex AI Model Monitoring: * Drift Detection: Identifies changes in prediction distributions or input feature statistical shifts (e.g., changes in image acquisition protocols).
- Alerting: Automated notifications via Cloud Monitoring when significant drift is detected.
- Attribution Monitoring: Uses techniques like SHAP to track if the model’s “reasoning” (feature importance) changes over time.
Implementation Plan Summary
- Infrastructure Setup: Configure secure GCS buckets and Vertex AI Notebook instances. Establish source control (GitHub/Cloud Source Repositories).
- Component Development: Create modular scripts for pre-processing, training, and evaluation.
- Orchestration: Package code into containers and define the initial Vertex AI Pipeline.
- Deployment: Register the lead model in the Registry and deploy to an Endpoint with active Monitoring.
- Continuous Improvement: Use monitoring alerts to trigger automated retraining and refine model architectures iteratively.
Workflow Orchestration Comparison
| Feature | Apache Airflow | Google Cloud Composer | Vertex AI Pipelines |
|---|---|---|---|
| Primary Purpose | General workflows | Managed Airflow | ML-specific orchestration |
| ML Focus | General purpose | General purpose | Built for ML |
| Environment | Flexible / On-prem | GCP | GCP (Vertex AI) |
| Management | Self-managed | Fully managed | Serverless |
| Scalability | Manual scaling | Scales on GCP | Auto-scales |
| Core Tech | Python DAGs | Apache Airflow | Kubeflow / TFX |
Vertex AI Pipeline Orchestration